Presidential excitable speech analysis (1)
본 프로젝트는 2회에 걸쳐 게시되었습니다. 첫 번째 게시물은 자료 수집과 전처리 및 산출식 개발 등에 초점을 맞추고, 두 번째 게시물은 본격적인 상관분석, 시각화와 주관적 분석을 다루고 있습니다.
목차
- 도입
- 간단한 소개
- 국정 지지도 자료 수집
- 문재앙 지수 만들기
- 댓글 크롤링
- 네이버
- 다음
- 국정 지지도와 초벌 상관 분석
- 인사이트 파악 및 산출식 개발
- 댓글 크롤링
간단한 소개
2018.2 ~ 문재인 현 대통령의 국정 지지도와 네이버/다음 메인 시사 뉴스 댓글 중 ‘문재앙’ 키워드를 포함한 댓글의 좋아요/싫어요 수치를 구한다. 이를 상관 분석을 통해 비교하고자 한다.
국정 지지도 자료 수집
현 대통령의 국정 지지도 수치는 국내 여론조사 기관 ‘한국갤럽’과 ’리얼미터’의 주간 집계자료를 이용하되, 위키백과 항목에 주간별로 정리된 테이블을 스프레드시트에 옮겨 R로 전처리 후 사용한다. 보다 세부적인 대통령 국정평가 항목, 즉 ’긍정평가’ ‘부정평가’ 수치는 각 여론조사 기관 홈페이지에 게재되는 주간 동향 보도자료 내 수치를 스프레드시트로 정리한 후 사용한다. cf. 구글 스프레드시트를 통해 크롤링하는 방법도 고려했지만, 여론조사 홈페이지 URL 링크의 불규칙성, 한글 주소의 인코딩 문제, PDF 파일 크롤링의 어려움 등을 감안해 주간 자료를 직접 table로 정리하는 것이 효율적이라고 판단했다.
국정 지지도 자료를 구하는 데에는 크게 2가지 경로가 있다. 하나는 위키백과 ‘대한민국의 대통령 지지율’ 항목에서 표로 정리된 리얼미터/한국갤럽 자료를 이용하는 것이고, 다른 하나는 해당 조사기관 홈페이지에 주마다 게시되는 보도자료를 직접 참조하는 것이다. 나는 일차적인 분석을 위해 간편한 위키백과 도표 자료를 이용하고, 일정한 인사이트를 얻은 후 해당 홈페이지에 게시된 보도자료의 더 상세한 수치를 직접 구글스프레드 시트 등으로 정리하여 R로 불러왔다.
# 조사기관 보도자료 내 긍정/부정평가 항목 데이터 불러오기 (리얼미터, 한국갤럽)
rlmeter_president = read_xlsx("poll_president.xlsx", sheet = 1, range = cell_cols("A:H"))
rlmeter_president## # A tibble: 120 x 8
## week 매우잘한다 잘하는편 잘못하는편 매우잘못함 잘한다 잘못한다
## <dttm> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2018-02-03 00:00:00 41.5 22 13.3 18.8 63.5 32.1
## 2 2018-02-10 00:00:00 43.8 19.3 12.4 19.1 63.1 31.5
## 3 2018-02-17 00:00:00 41.7 24 11 17.9 65.7 28.9
## 4 2018-02-24 00:00:00 42 23.5 12 18.6 65.5 30.6
## 5 2018-03-03 00:00:00 44.8 21 12.5 15.7 65.8 28.2
## 6 2018-03-10 00:00:00 49.2 20.4 10.5 13.3 69.6 23.8
## 7 2018-03-17 00:00:00 49.3 19.8 10.5 16.1 69.1 26.6
## 8 2018-03-24 00:00:00 48.6 20.9 11.1 14.5 69.5 25.6
## 9 2018-03-31 00:00:00 46.7 21.4 11.8 13.9 68.1 25.7
## 10 2018-04-07 00:00:00 42.9 23.9 11.6 15.1 66.8 26.7
## # … with 110 more rows, and 1 more variable: 모름 <dbl>gallup_president = read_xlsx("poll_president.xlsx", sheet = 2, range = cell_cols("B:H"))
gallup_president = bind_cols(gallup_president[1:120,], rlmeter_president[,1]) %>%
select(week, everything(), -`월(M)`, -`주(W)`, -`표본 수`)
gallup_president## # A tibble: 120 x 5
## week g잘하고있다 g잘못하고있다 g어느쪽도아니다 g모름응답거절
## <dttm> <dbl> <dbl> <dbl> <dbl>
## 1 2018-02-03 00:00:00 0.63 0.28 0.04 0.05
## 2 2018-02-10 00:00:00 NA NA NA NA
## 3 2018-02-17 00:00:00 0.68 0.22 0.05 0.04
## 4 2018-02-24 00:00:00 0.64 0.26 0.04 0.06
## 5 2018-03-03 00:00:00 0.71 0.22 0.04 0.04
## 6 2018-03-10 00:00:00 0.74 0.18 0.05 0.04
## 7 2018-03-17 00:00:00 0.71 0.19 0.06 0.05
## 8 2018-03-24 00:00:00 0.7 0.21 0.05 0.04
## 9 2018-03-31 00:00:00 0.74 0.17 0.05 0.04
## 10 2018-04-07 00:00:00 0.72 0.19 0.05 0.04
## # … with 110 more rows# 위키백과 '대통령 지지도' 항목에서 긁어온 데이터 전처리
wiki = read_xlsx("wiki_president.xlsx")par(mfrow=c(2,1))
plot.ts(wiki$gallup)
plot.ts(wiki$rlmeter)
위키백과 항목의 결측값 탓에 푹 꺼진 부분을 제외하고 대강의 추세를 살펴보면, 지난 약 2년여간 대통령의 지지율은 꾸준히 감소해왔음을 알 수 있다. 이는 집권 중반기를 지난 탓에 통상적인 레임덕 현상이 나타났음으로 보이며, 다만 코로나 사태에 대해 성공적인 국정 운영으로 평가받는 최근에 들어서는 지지율이 다소 상승한 추세를 확인할 수 있다.
문재앙 지수 만들기 (1) 댓글 크롤링
네이버 기사 링크 추출
댓글을 크롤링할 기사로 뉴스 랭킹 배너에 조회수 기준 일간 상위 30개의 기사(부문별 5개, 총 6개 부문)을 선정한다.
네이버 ‘많이 본 기사’ 랭킹 배너 링크를 들어가보면, (“https://news.naver.com/main/ranking/popularDay.nhn?rankingType=popular_day&date=20180212”)(2018.2.12일자) 일간 누적 집계된 조회수 기준 상위 30개의 6개 부문 기사 제목과 링크가 나열되어 있는 것을 확인할 수 있다. 우리는 여기서 구글 스프레드 시트의 importxml() 함수와 xpath 정규 표현식을 활용하여 일자별 30개의 기사 링크를 긁어올 수 있다. 여기서 랭킹 배너의 링크에는 일정한 규칙성이 있으므로, 랭킹 배너에 접근할 URL은 main_url(“https://news.naver.com”)에 sub_url 변수를 for문을 통해 조합하는 방식으로 마련하였다. 조사 대상 날짜인 2018.02.06 ~ 2020.06. ** 에서 일자별 자동 추출된 30개의 기사링크는 구글 스프레드시트에 쌓고 “naver_df.xlsx” 파일로 추출한 후 이를 R로 불러온다.
+) 위와 같이 기사 링크를 추출하는 방식은 importxml() 함수를 사용하기 위해 구글 스프레드시트를 거쳐야 하는 불편함이 다소 있었다. 따라서 ‘다음’ 기사 링크를 추출할 때는 Rstudio 내에서 해당 크롤링 작업을 할 수 있도록 하였다. 즉, ‘xml2’ 패키지의 read_html() 함수와 ‘rvest’ 패키지의 html_nodes() 함수 등을 이용하여 랭킹 배너의 html 소스코드에 열거된 상위 10개 기사의 링크를 가져오도록 했다. (하단 코드 참조)
댓글 필터링 및 크롤링, 좋아요/싫어요 수 합산
크롤링할 댓글 양이 상당하다는 점을 감안해 이미 마련된 패키지를 활용하기로 한다. 사용할 패키지는 N2H4, DNH4이며, 각각 네이버/다음 내부 기사 URL을 인자로 넣으면 해당 기사에 달린 댓글과 좋아요/싫어요 수 등 다양한 변수를 크롤링해준다. 현재까지 문재앙 지수를 산출하는 데 필요한 변수들은 다음과 같다.
- 일간 상위 30개 기사에 달린 모든 댓글의 좋아요/싫어요 총합
- ‘문재앙’ 및 관련 어휘가 포함/제외된 모든 댓글의 좋아요/싫어요 총합
- ‘문재앙’ 및 관련 어휘가 포함/제외된 모든 댓글 수
그런데 이때, 우리는 타당한 지수 산출을 위해 매크로 및 유령 계정 활용, ‘좌표 찍기’를 비롯한 댓글상의 정치 공작 등의 불필요한 과도표집을 예방해야 할 것이다. 따라서 특정 댓글 내용을 아예 똑같이 복사한 경우인 기사 내/(동일 일자) 기사 간 중복댓글을 표본에서 배제하고, 중복댓글 중 시간상 마지막에 달린 단 1개의 댓글만을 표본에 반영할 것이다. 또한 ’문재앙’ 어휘를 포함한 임의의 1000개 댓글을 훑어본 결과, 100개당 1-2개꼴로 현 대통령을 지지하는 댓글을 발견했는데, 대체로 ‘문재앙 타령’ 이라고 말하는 식이었다. 따라서 ’문재앙’이라는 어휘가 포함된 댓글 중 ’타령’이라는 어휘가 없거나, ’탄핵’이라는 강한 부정어를 포함하는 댓글을 수집하는 것으로 2차 필터링을 거쳤다.
main_url = "https://news.naver.com"
operator = "/main/ranking/popularDay.nhn?rankingType=popular_day&date="
datelist = read_xlsx("datelist.xlsx", range = cell_cols("B")) %>% as_tibble()
Summary_3 = tibble()
for (j in 1:nrow(datelist)){
Summary_1 = tibble()
Summary_2 = tibble()
tmp_1 = tibble()
tmp_2 = tibble()
date = datelist[j,1]
doc = read_html(str_c(main_url, operator, date))
tmp = html_nodes(doc, 'dl') %>% html_nodes('a') %>% html_attr("href")
tic()
for (i in 1:30){
sub_url = tmp[i]
tmp_1 = getAllComment(str_c(main_url, sub_url)) %>%
as_tibble() %>%
filter(!duplicated(contents)) %>%
select(contents, ends_with("Count"), -imageCount)
Summary_1 = bind_rows(Summary_1, tmp_1)
tmp_2 = tmp_1 %>%
filter(str_detect(contents, "문재앙")) %>%
filter(!str_detect(contents, "타령")) %>%
select(contents, ends_with("Count"))
Summary_2 = bind_rows(Summary_2, tmp_2)}
toc()
nrow = nrow(Summary_1)
nrow_1 = nrow(Summary_2)
Summary_1 = Summary_1 %>%
filter(!duplicated(contents))
like = sum(Summary_1$sympathyCount)
dislike = sum(Summary_1$antipathyCount)
Summary_2 = Summary_2 %>%
filter(!duplicated(contents))
like_1 = sum(Summary_2$sympathyCount)
dislike_1 = sum(Summary_2$antipathyCount)
Summary_3[j, 1] = ymd(date)
Summary_3[j, 2] = like
Summary_3[j, 3] = dislike
Summary_3[j, 4] = nrow
Summary_3[j, 5] = like_1
Summary_3[j, 6] = dislike_1
Summary_3[j, 7] = nrow_1
print(ymd(date))}
write.csv(Summary_3, "Summary_df_5.csv")
Summary_3$week = as.Date(cut(Summary_3$...1, breaks = "week", start.on.monday = FALSE)) - 1
Summary_3
for (i in 2:767){
Summary_3$week[i-1] = Summary_3$week[i]}다음 기사 링크 추출
‘다음’의 경우 랭킹 뉴스 배너 조회수 기준 일자별 상위 10개 기사를 댓글 추출 대상으로 한다. (’2019 언론수용자 조사’의 포털별 뉴스 점유율에 따라(네이버 91%, 다음 20%, 중복응답) 기사 갯수를 선정했다.) 크롤링 코드는 다음과 같다. 앞서 언급한대로 ’xml2’, ‘rvest’ 패키지 내장 함수를 통해 html 소스코드에서 일자별 기사 링크를 추출하고 해당 링크 기사에 달린 댓글들에 접근하는 방식을 취하였다. 이떄 사용한 ‘DNH4’ 패키지의 getAllComment() 함수는 패키지상의 오류가 발생하곤 했으므로 상응하는 예외처리를 거쳤다.
library(DNH4)
main_url = "https://media.daum.net/ranking/popular"
operator = "?regDate="
datelist = read_xlsx("datelist.xlsx", range = cell_cols("B")) %>% as_tibble()
linklist = list()
Summary_4 = tibble()
print(datelist, n = 300)
for (i in 1:nrow(datelist)){
Summary_1 = tibble()
Summary_2 = tibble()
date = datelist[i,1]
doc = read_html(str_c(main_url, operator, date))
tmp = html_nodes(doc, 'li') %>% html_nodes('a') %>% html_attr("href")
linklist = unique(tmp[44:63])
for (j in 1:length(linklist)){
tic()
tmp_1 = tibble()
tmp_2 = tibble()
sub_url = linklist[j]
if(is_null(tryNULL(getAllComment(sub_url)))){next} else {
tmp_1 = getAllComment(sub_url) %>% as.data.table() %>%
as_tibble() %>%
filter(!duplicated(content)) %>%
select(content, likeCount, dislikeCount)
Summary_1 = bind_rows(Summary_1, tmp_1)
tmp_2 = tmp_1 %>%
filter(str_detect(content, "문재앙")) %>%
filter(!str_detect(content, "타령")) %>%
select(content, likeCount, dislikeCount)
Summary_2 = bind_rows(Summary_2, tmp_2)}}
toc()
Summary_1 = Summary_1 %>%
filter(!duplicated(content))
nrow = nrow(Summary_1)
like = sum(Summary_1$likeCount)
dislike = sum(Summary_1$dislikeCount)
Summary_2 = Summary_2 %>%
filter(!duplicated(content))
nrow_1 = nrow(Summary_2)
like_1 = sum(Summary_2$likeCount)
dislike_1 = sum(Summary_2$dislikeCount)
Summary_4[i-1, 1] = date
Summary_4[i-1, 2] = like
Summary_4[i-1, 3] = dislike
Summary_4[i-1, 4] = nrow
Summary_4[i-1, 5] = like_1
Summary_4[i-1, 6] = dislike_1
Summary_4[i-1, 7] = nrow_1
print(i)}daum_disaster_reply = read_xlsx("daum_disaster_reply.xlsx")daum_disaster_reply## # A tibble: 4,583 x 3
## content likeCount dislikeCount
## <chr> <dbl> <dbl>
## 1 "문재앙이 기래기" 1 0
## 2 "문재앙, 공산당이 싫어요" 0 3
## 3 "김대중좌빨세끼 국민연금만들고 실실 .... 노무현좌빨세끼 도로명주소법제화시키고 실실.... 문… 0 1
## 4 "문재앙 정권이 그렇지 뭐" 2 3
## 5 "경찰놈들도 문재앙" 1 2
## 6 "문재앙식 문주주의 크라스에 지렸습니다" 1 4
## 7 "문재앙 미 친 새 퀴 때문에 장사 안되는데 ~ 세금만 뜯어 가려 하네? 미 친 놈들 ㅉㅉ"… 2 3
## 8 "문재앙\n부실기업\n민노총나라국민은제편이라\n마구처발라주고\n되는기업은\n먼지탈탈털어구속"… 0 11
## 9 "뭘 그리 놀래나. \n문재앙정부 하는일이 다 그렇치 뭐,, ㅋ"… 2 0
## 10 "응 문재앙" 0 1
## # … with 4,573 more rows‘문재앙’ 어휘를 포함한 댓글이 수집된 데이터를 살펴보자. (예외처리를 거친) 대략 845일간의 ‘문재앙’ 댓글 전량을 수집하였음에도 4500개 댓글뿐으로, 이는 하루 5개 정도의 댓글만이 ‘문재앙’ 어휘를 사용했음을 뜻한다. 다음 플랫폼 주 이용자의 정치적 성향을 고려하더라도 이는 상당히 적은 양의 댓글 수이므로 독립적인 표본으로서 결과에 반영하기 애매한듯 보이므로 우선은 분석 대상에서 제외하는 것이 나을 것 같다.
문재앙 지수 만들기 (2) 국정 지지도와 초벌 상관 분석
이제 수집된 네이버 댓글 데이터와 위키백과의 ‘대통령 지지도’ 항목에 제시된 국정평가 도표 수치를 비교해보자. 대강의 상관관계를 파악하는 데 도움을 줄 것이다.
cor(Summary_3[1:119,1:6], wiki[,c("gallup", "rlmeter")])## gallup rlmeter
## like_all 0.27487891 0.39347760
## dislike_all 0.22859883 0.36233054
## num_all 0.23600060 0.27587070
## like_1 -0.11599185 -0.05721397
## dislike_1 0.03731947 0.11840819
## num_1 0.05650117 0.06989181다소 뜻밖에 결과를 알 수 있는데, ‘문재앙’ 어휘 포함 댓글의 수, 좋아요/싫어요 수치보다 전체 댓글 수, 좋아요, 싫어요 수가 다소 높은 상관을 보이는 것으로 드러나기 때문이다. 따라서 크롤링한 요인들을 활용하여 산출식을 정교화해야 높은 상관관계를 얻을 수 있겠다고 생각된다. 이쯤에서 조사기간(2018.2 ~ 2020.05) 내 전체 댓글 추이를 한번 살펴보자.
ggplot(Summary, aes(x = week, y = num_all)) +
geom_line() +
xlab("조사기간\n(2018년 2월 첫째주 ~ 2020년 5월 셋째주)")+
ylab("네이버 뉴스 전체 댓글 수")+
scale_y_continuous(breaks = 100000*c(2:5), labels = c("200000개", "300000개", "400000개", "500000개"))+
theme_bw()+
geom_smooth(method = "loess")## `geom_smooth()` using formula 'y ~ x'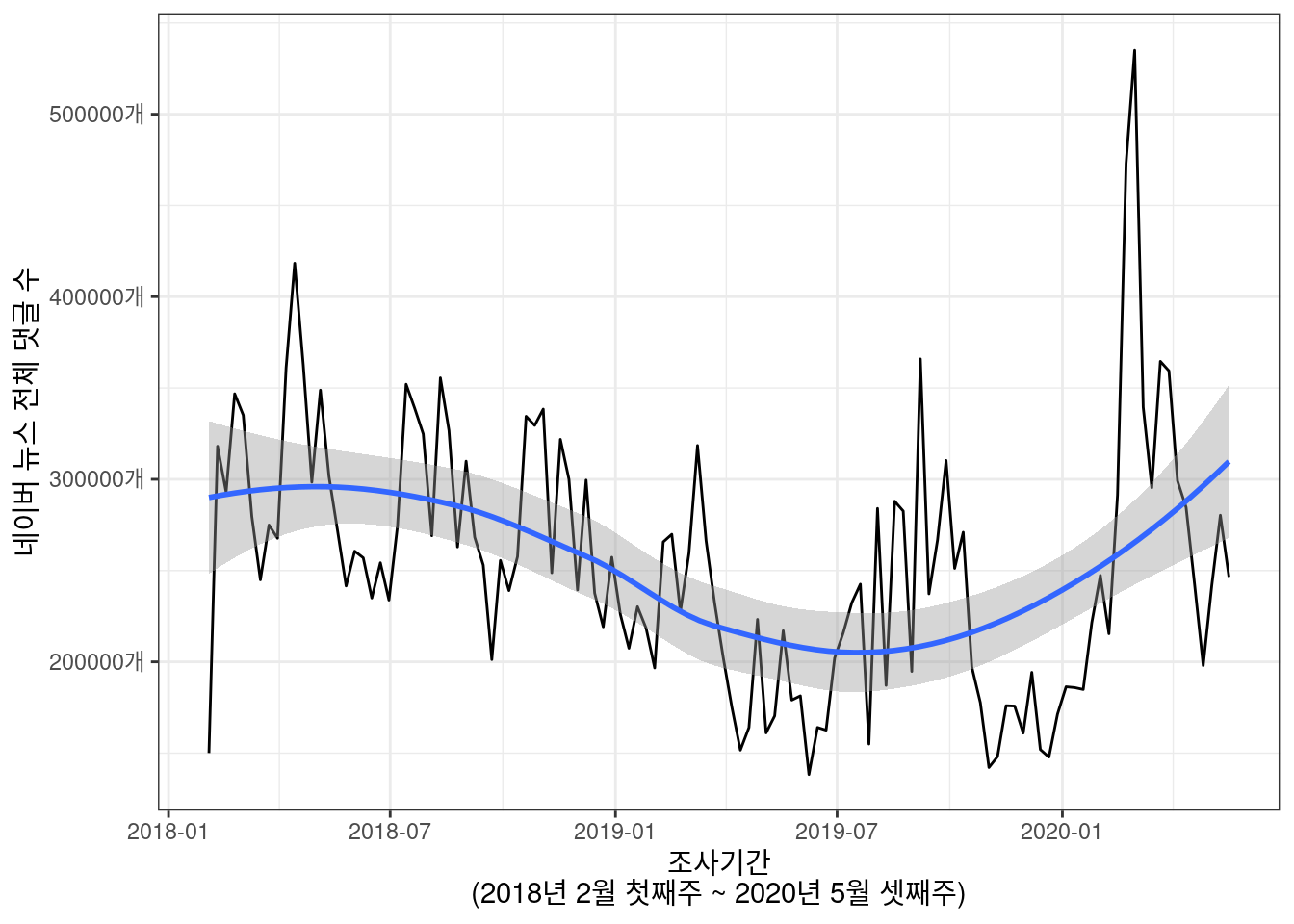
loess 추세선과 함께 살펴보면, 네이버 뉴스창의 (랭킹 배너 일간 조회수 top30 기사 한정) 댓글 수는 꾸준히 감소해 온 것을 알 수 있다. 다만 올해 들어 코로나 사태 영향으로 댓글창이 일시적으로 활발해진 추세도 함께 엿볼 수 있다. 이렇듯 꾸준한 감소세는 앞서 살펴 본 위키백과 항목의 대통령 지지율의 꾸준한 감소와 유사한 패턴을 보이지만, 이 두 가지 현상, 즉 현 대통령의 레임덕과 (이유 모를) 네이버 댓글창의 비활성화가 유의미한 상관관계를 갖는 사회적 현상인지는 의문이다.
문재앙 지수 만들기 (3) 인사이트 파악 후 산출식 수정
여기서 나아가 다른 어휘들은 어떤 상관관계가 있을지까지 파악해 보기로 했다. 코드는 다음과 같다. (네이버 서버상의 문제인지 같은 일자에서 계속해서 오류가 발생했다. 따라서 for문을 돌리는 와중에 중간중간 오류 발생 시 예외처리를 하고 코드 실행을 재개해야 한다.)
main_url = "https://news.naver.com"
operator = "/main/ranking/popularDay.nhn?rankingType=popular_day&date="
datelist = read_xlsx("datelist.xlsx", range = cell_cols("B")) %>% as_tibble()
# datelist = datelist[774:844, 1]
Summary_3 = tibble()
for (j in 1:nrow(datelist)){
Summary_2 = tibble()
Summary_4 = tibble()
Summary_5 = tibble()
Summary_6 = tibble()
date = datelist[j,1]
doc = read_html(str_c(main_url, operator, date))
tmp = html_nodes(doc, 'dl') %>% html_nodes('a') %>% html_attr("href")
tic()
tmp_1 = tibble()
tmp_2 = tibble()
tmp_3 = tibble()
tmp_4 = tibble()
tmp_5 = tibble()
for (i in 1:30){
sub_url = tmp[i]
tmp_1 = getAllComment(str_c(main_url, sub_url)) %>%
as_tibble() %>%
filter(!duplicated(contents)) %>%
select(contents, ends_with("Count"), -imageCount)
tmp_2 = tmp_1 %>%
filter(str_detect(contents, "문죄인")) %>%
filter(!str_detect(contents, "일베")) %>%
filter(!str_detect(contents, "타령")) %>%
select(contents, ends_with("Count"))
Summary_2 = bind_rows(Summary_2, tmp_2)
tmp_3 = tmp_1 %>%
filter(str_detect(contents, "중국몽")) %>%
filter(!str_detect(contents, "일베")) %>%
filter(!str_detect(contents, "타령")) %>%
select(contents, ends_with("Count"))
Summary_4 = bind_rows(Summary_4, tmp_3)
tmp_4 = tmp_1 %>%
filter(str_detect(contents, "문슬람")) %>%
filter(!str_detect(contents, "일베")) %>%
filter(!str_detect(contents, "타령")) %>%
select(contents, ends_with("Count"))
Summary_5 = bind_rows(Summary_5, tmp_4)
tmp_5 = tmp_1 %>%
filter(str_detect(contents, "대깨문")) %>%
filter(!str_detect(contents, "일베")) %>%
filter(!str_detect(contents, "타령")) %>%
select(contents, ends_with("Count"))
Summary_6 = bind_rows(Summary_6, tmp_5)}
toc()(엑셀 스프레드시트로 변수명 변경 및 열 배치 등 간단한 전처리를 했다.)
나아가, 보다 구체적이고 유의미한 결과 도출을 위해 나는 주 단위 단순 긍정/부정평가 항목 이외에 ‘정치성향별 국정평가’ 항목 및 일 단위 긍정/부정평가 항목 수치까지 수집했다. 방식은 역시 주간집계 PDF 보고서 파일에서 스프레드시트로 일일이 복사+붙여넣기하는 노가다에 가까웠는데, 이 과정을 효율적으로 운용하기 위해서는 여론조사 기관의 간결한 결과 제시가 필요해 보인다.
자, 이제 우리는 다양한 산출식을 생각해 볼 수 있다. 나는 우선 3가지 산출식 옵션을 생각했는데, 3가지 옵션은 다음과 같다.
1. 전체 좋아요 수 / (전체 좋아요 + 싫어요 수) - 문재앙 좋아요 수 / (문재앙 좋아요 + 싫어요 수)
2. 좋아요 수 / (좋아요 + 싫어요 수)
3. {(좋아요 + 싫어요 수) / 좋아요 수}*log(단어 포함 댓글 수/전체 댓글 수)
한눈에 보기에도 가장 간단한 식은 2번이다. 비하 단어를 포함한 댓글의 주간 좋아요 수와 싫어요 수 합산만 고려하면 된다. 여기에 주간 댓글 좋아요/싫어요 동향을 반영하여 두 수치를 빼면 1번 식이 나오고, 주간 댓글 좋아요/싫어요 동향을 반영하는 대신, 주간 전체 댓글 수 대비 비하 단어 포함 작성된 댓글 수 비율의 가중치를 두면 3번 식이 나온다. 이때 비하 단어 포함 댓글은 전체 댓글에 비해 상당히 적은 비율을 갖고 있기 때문에 이를 고려하여 로그 변환을 해주는 것이 나을 것이라 판단했다.
댓글 및 좋아요/싫어요 수가 상식적으로 나온다면, 1번과 3번 식은 국정 지지도와 정적 상관을, 2번 식은 부적 상관을 가지게 될 것이다. 정말로 그러한지 확인해볼겸 나는 1차적인 수식 검증을 할 것이다. 5개의 비하 단어와 32개의 기본 국정평가 항목 중 각각이 얼마큼 유의미한 상관관계를 갖는지 확인한다. 160개의 항목 중 유의도 .05를 넘는 항목의 갯수가 크게 낮으면 정확한 지수 산출식이라고 볼 수 없을 것이다.
예시
Option 1.
전체 좋아요 수 / (전체 좋아요 + 싫어요 수) - 문재앙 좋아요 수 / (문재앙 좋아요 + 싫어요 수)
Summary.df = Summary %>%
mutate(disaster = like_all/(like_all+dislike_all) - (like_1)/(like_1+dislike_1),
sinner = like_all/(like_all+dislike_all) - (like_2)/(like_2+dislike_2),
china = like_all/(like_all+dislike_all) - (like_3)/(like_3+dislike_3),
islam = like_all/(like_all+dislike_all) - (like_4)/(like_4+dislike_4),
head = like_all/(like_all+dislike_all) - (like_5)/(like_5+dislike_5)) %>%
select(week, disaster, sinner, china, islam, head, everything())
Summary.df = full_join(Summary.df, rlmeter_president, by = "week") %>%
full_join(gallup_president, by = "week") %>%
select(-week) %>%
bind_cols(ideo) %>%
select(-week)
mySumm = tibble()
for (i in colnames(Summary.df[1:5])){
for (j in colnames(Summary.df[24:55])){
formula = as.formula(str_c("~",i,"+",j))
myCorr = cor.test(formula, data = Summary.df) %>% tidy()
myCorr$word = i
myCorr$eval = j
mySumm = bind_rows(myCorr, mySumm)
}
}
mySumm %>% arrange(p.value) %>%
select(word, eval, estimate, everything(), -method) %>%
filter(p.value<.05)## # A tibble: 106 x 9
## word eval estimate statistic p.value parameter conf.low conf.high
## <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 disa… g잘하고… 0.653 8.91 1.46e-14 107 0.530 0.749
## 2 disa… 매우잘한… 0.636 8.79 1.81e-14 114 0.513 0.733
## 3 disa… g잘못하… -0.647 -8.77 3.04e-14 107 -0.744 -0.522
## 4 disa… 잘한다… 0.627 8.59 5.27e-14 114 0.502 0.726
## 5 disa… 잘못한다… -0.626 -8.57 5.78e-14 114 -0.725 -0.501
## 6 sinn… 진보잘못… -0.630 -8.58 6.19e-14 112 -0.729 -0.504
## 7 sinn… 매우잘한… 0.622 8.47 9.67e-14 114 0.495 0.722
## 8 disa… 진보잘못… -0.624 -8.45 1.21e-13 112 -0.725 -0.497
## 9 disa… 중도잘한… 0.620 8.35 1.98e-13 112 0.492 0.721
## 10 disa… 중도잘못… -0.619 -8.33 2.23e-13 112 -0.721 -0.490
## # … with 96 more rows, and 1 more variable: alternative <chr># option 2
mySumm %>% arrange(p.value) %>%
select(word, eval, estimate, everything(), -method) %>%
filter(p.value<.05)## # A tibble: 108 x 9
## word eval estimate statistic p.value parameter conf.low conf.high
## <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 disa… 잘한다… -0.668 -9.59 2.54e-16 114 -0.758 -0.553
## 2 disa… 잘못한다… 0.665 9.50 4.02e-16 114 0.549 0.756
## 3 disa… 중도잘한… -0.669 -9.53 4.03e-16 112 -0.760 -0.553
## 4 disa… 매우잘한… -0.664 -9.48 4.48e-16 114 -0.755 -0.548
## 5 disa… 중도잘못… 0.667 9.48 5.20e-16 112 0.551 0.758
## 6 disa… 보수매우… 0.660 9.30 1.34e-15 112 0.542 0.753
## 7 disa… 보수잘못… 0.659 9.27 1.61e-15 112 0.540 0.752
## 8 disa… 중도매우… -0.658 -9.24 1.87e-15 112 -0.751 -0.539
## 9 disa… 보수매우… -0.653 -9.13 3.32e-15 112 -0.747 -0.533
## 10 disa… g잘하고… -0.661 -9.12 5.07e-15 107 -0.755 -0.540
## # … with 98 more rows, and 1 more variable: alternative <chr># option 3
mySumm.2 %>% arrange(p.value) %>%
select(word, eval, estimate, everything(), -method) %>%
filter(p.value<.05)## # A tibble: 121 x 9
## word eval estimate statistic p.value parameter conf.low conf.high
## <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 head 중도잘못… 0.779 13.1 2.05e-24 112 0.694 0.842
## 2 head 중도잘한… -0.772 -12.9 8.41e-24 112 -0.837 -0.686
## 3 head 중도매우… 0.765 12.6 3.95e-23 112 0.676 0.832
## 4 head 보수잘못… 0.762 12.5 6.59e-23 112 0.673 0.830
## 5 head 보수매우… 0.761 12.4 8.01e-23 112 0.672 0.829
## 6 head 매우잘못… 0.757 12.4 8.99e-23 114 0.666 0.825
## 7 head 잘못한다… 0.756 12.3 9.72e-23 114 0.666 0.825
## 8 head 보수잘한… -0.752 -12.1 5.60e-22 112 -0.822 -0.659
## 9 head 잘한다… -0.737 -11.6 3.91e-21 114 -0.811 -0.641
## 10 head 중도매우… -0.722 -11.0 1.33e-19 112 -0.799 -0.620
## # … with 111 more rows, and 1 more variable: alternative <chr>위와 같은 코드로 3개의 산출식을 계산했을 때 각각 106, 108, 121개의 유의미한 항목 결과가 나온다. 모름/무응답 항목도 포함된 만큼 세 가지 산출식 모두 다소 유의한 항목 갯수라고 볼 수 있을 듯하다. 2번 산출식에서 전체 댓글 좋아요 주간 동향을 반영한 1번 산출식이 조금 더 유의도가 떨어졌다는 점에서 ‘비하 단어’ 포함 댓글은 전체 댓글의 좋아요 수를 고려하지 않았을 때 더욱 여론의 효과적인 재현 지표로 볼 수 있다는 것을 알 수 있다. 또한 3번 산출식이 정확도가 가장 높아보이는데, 2번과 3번의 scattorplot을 보자.
## Option 2
par(mfrow = c(2, 2))
plot(Summary.df$disaster, Summary.df.2$잘못한다, main = "문재앙 지수")
plot(Summary.df$sinner, Summary.df.2$잘못한다, main = "문죄인 지수")
plot(Summary.df$islam, Summary.df.2$잘못한다, main = "문슬람 지수")
plot(Summary.df$head, Summary.df.2$잘못한다, main = "대깨문 지수")
## Option 3
par(mfrow = c(2, 2))
plot(Summary.df.2$disaster, Summary.df.2$잘못한다, main = "문재앙 지수")
plot(Summary.df.2$sinner, Summary.df.2$잘못한다, main = "문죄인 지수")
plot(Summary.df.2$islam, Summary.df.2$잘못한다, main = "문슬람 지수")
plot(Summary.df.2$head, Summary.df.2$잘못한다, main = "대깨문 지수")
어떤 지수를 활용할 지는 우리 마음이지만, 나는 가장 단순한 2번 산출식과 estimate가 가장 높은 항목을 도출한 3번 산출식 이 두 가지 지표를 모두 활용해서 각각 시각화해보기로 했다. 본격적인 시각화와 상응하는 주관적 분석에 대해서는 다음 게시물에서 다루도록 하겠다.
(2편에 계속)