Presidential excitable speech analysis (2)
본 프로젝트는 2회에 걸쳐 게시되었습니다. 첫 번째 게시물은 자료 수집과 전처리 및 산출식 개발 등에 초점을 맞추고, 두 번째 게시물은 본격적인 상관분석, 시각화와 주관적 분석을 다루고 있습니다.
목차
- 도입
- 간단한 소개
- 지난 게시물에서는
- 상관분석 및 시각화
- 상관분석
- 시각화
- 단어별 시각화
- 부정/긍정평가 시각화
- 급진/중도평가 시각화
- 상관관계 추이 시각화
- 대시보드화
- 주관적 분석
간단한 소개
2018.2 ~ 문재인 현 대통령의 국정 지지도와 네이버/다음 메인 시사 뉴스 댓글 중 ‘문재앙’ 키워드를 포함한 댓글의 좋아요/싫어요 수치를 구한다. 이를 상관 분석을 통해 비교하고자 한다.
지난 게시물에서는
지난번 게시물에서는 N2H4와 xml2, rvest 등의 패키지를 이용하여 네이버 랭킹 배너 조회수 기준 top 30개 기사에 달린 댓글 수와 좋아요/싫어요 갯수를 크롤링하고, 크롤링한 댓글 관련 데이터와 여론조사 기관의 국정 지지도 데이터를 상관분석할 수 있도록 전처리하는 작업을 서술했다. 이번에는 전처리하고 scatterplot으로 살펴본 데이터를 상관분석하고 시각화하여 이를 바탕으로 나름의 주관적 분석을 해볼까한다.
분석에 활용할 댓글 크롤링 데이터는 다음과 같다. 비하 단어 5개(순서대로 ‘문재앙’, ‘문죄인’, ‘중국몽’, ‘문슬람’, ‘대깨문’)의 댓글 수(num_), 좋아요 수(like_), 싫어요 수(dislike_)가 순서대로 수집된 된 것을 확인할 수 있다.
Summary## # A tibble: 120 x 19
## like_all dislike_all num_all like_1 dislike_1 num_1 like_2 dislike_2 num_2
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 3205941 907208 150062 88552 41136 3065 33273 9399 803
## 2 7317042 1745848 318100 156497 66183 7673 25083 10517 1675
## 3 6700141 1290108 292988 179743 48236 6897 42685 10651 1683
## 4 8016580 1985358 346844 88526 36852 6563 20147 9517 1732
## 5 6937595 1204274 335147 42375 16495 3886 11595 4082 1027
## 6 5430342 1108540 279648 41482 22111 3455 7675 3718 868
## 7 4309517 885848 244927 27128 11087 3089 8296 3695 908
## 8 5387709 1069080 274960 67028 22238 4785 13658 4743 1209
## 9 4920489 1035519 267698 34338 16508 3727 11035 5376 1120
## 10 7245289 955180 361099 34102 16273 4069 14388 4761 1083
## # … with 110 more rows, and 10 more variables: like_3 <dbl>, dislike_3 <dbl>,
## # num_3 <dbl>, like_4 <dbl>, dislike_4 <dbl>, num_4 <dbl>, like_5 <dbl>,
## # dislike_5 <dbl>, num_5 <dbl>, week <dttm>그리고 지난 게시물 마지막에 보았던 scatterplot을 다시 보는 것으로 시작하자.
Option 2는 좋아요 수 / (좋아요 + 싫어요 수)
Option 3는 {(좋아요 + 싫어요 수) / 좋아요 수}*log(단어 포함 댓글 수/전체 댓글 수)
## Option 2
par(mfrow = c(2, 2))
plot(Summary.df$disaster, Summary.df.2$잘못한다, main = "문재앙 지수")
plot(Summary.df$sinner, Summary.df.2$잘못한다, main = "문죄인 지수")
plot(Summary.df$islam, Summary.df.2$잘못한다, main = "문슬람 지수")
plot(Summary.df$head, Summary.df.2$잘못한다, main = "대깨문 지수")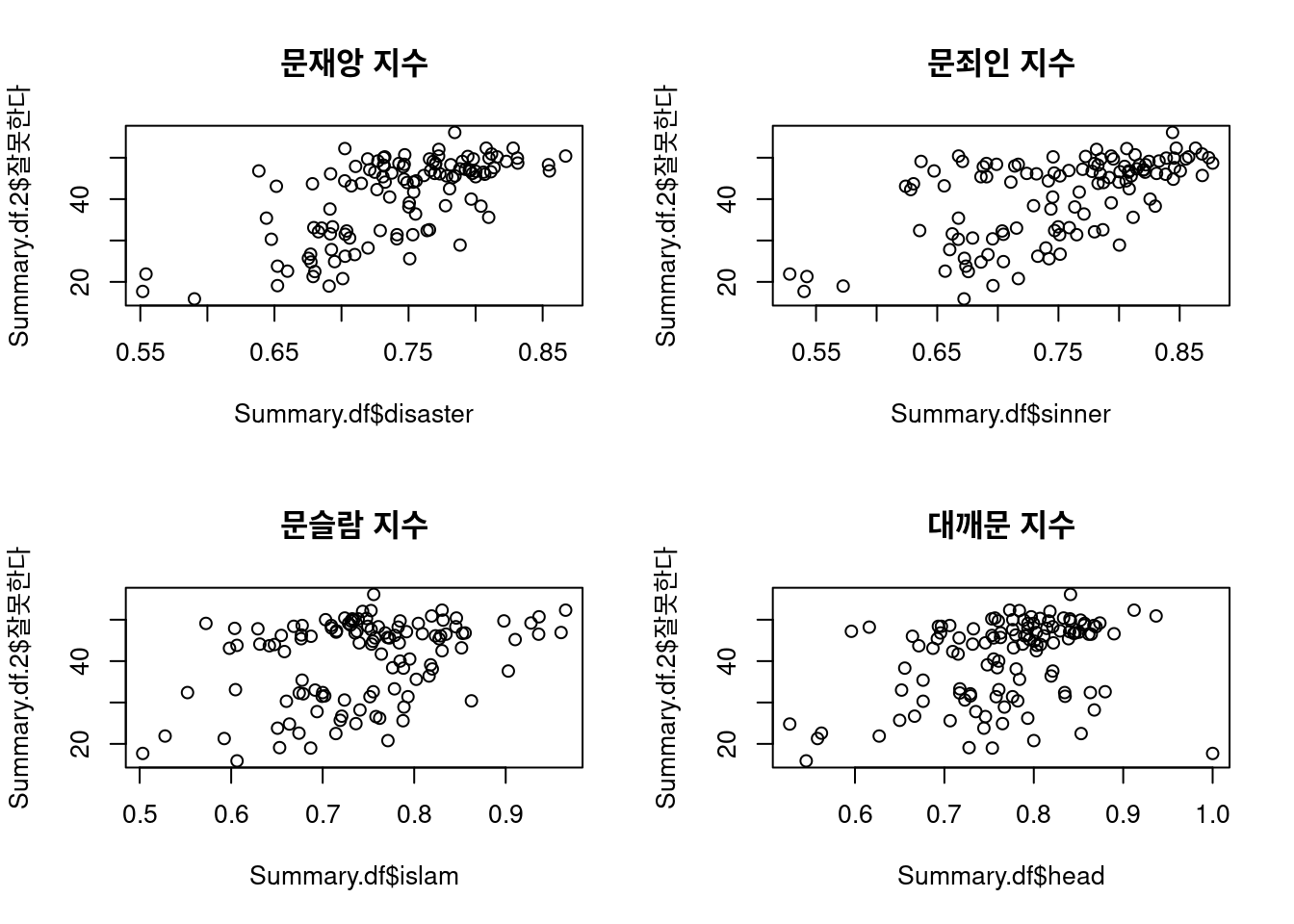
## Option 3
par(mfrow = c(2, 2))
plot(Summary.df.2$disaster, Summary.df.2$잘못한다, main = "문재앙 지수")
plot(Summary.df.2$sinner, Summary.df.2$잘못한다, main = "문죄인 지수")
plot(Summary.df.2$islam, Summary.df.2$잘못한다, main = "문슬람 지수")
plot(Summary.df.2$head, Summary.df.2$잘못한다, main = "대깨문 지수")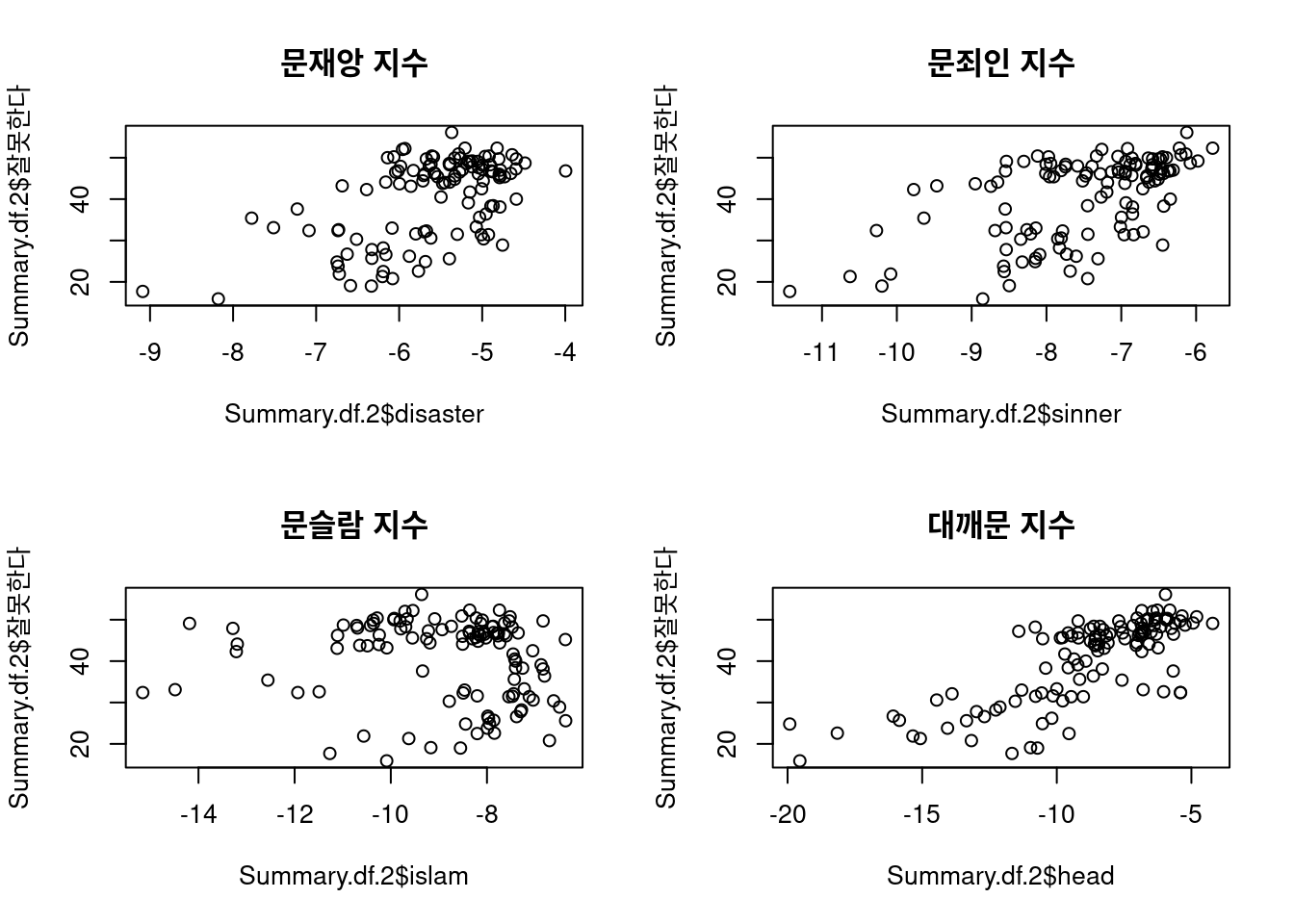
어떤 지수를 사용할지는 우리 마음이지만, 두 개의 지수에 따른 데이터 분포는 약간 다른 형태를 보여준다. 추후 시각화된 그래프를 살펴보면 어떤 특성에 따라 다르게 나타나는지 확인할 수 있으며 이는 개별 비하 단어 사용의 특성(맥락, 어감, 비하 대상) 등의 차이를 암시한다.
상관분석
그렇다면 5개 단어와 여론조사 평가항목(한국갤럽 및 리얼미터) 11개 및 정치성향별(보수/진보/중도) 평가항목 21개를 합한 총 32개의 평가항목 간의 피어슨 상관계수는 어떻게 나타났을까?
# option 2
mySumm %>% arrange(p.value) %>%
select(word, eval, estimate, everything(), -method) %>%
filter(p.value<.05) %>% print(n = 30)## # A tibble: 108 x 9
## word eval estimate statistic p.value parameter conf.low conf.high
## <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 disa… 잘한다… -0.668 -9.59 2.54e-16 114 -0.758 -0.553
## 2 disa… 잘못한다… 0.665 9.50 4.02e-16 114 0.549 0.756
## 3 disa… 중도잘한… -0.669 -9.53 4.03e-16 112 -0.760 -0.553
## 4 disa… 매우잘한… -0.664 -9.48 4.48e-16 114 -0.755 -0.548
## 5 disa… 중도잘못… 0.667 9.48 5.20e-16 112 0.551 0.758
## 6 disa… 보수매우… 0.660 9.30 1.34e-15 112 0.542 0.753
## 7 disa… 보수잘못… 0.659 9.27 1.61e-15 112 0.540 0.752
## 8 disa… 중도매우… -0.658 -9.24 1.87e-15 112 -0.751 -0.539
## 9 disa… 보수매우… -0.653 -9.13 3.32e-15 112 -0.747 -0.533
## 10 disa… g잘하고… -0.661 -9.12 5.07e-15 107 -0.755 -0.540
## 11 disa… g잘못하… 0.661 9.11 5.21e-15 107 0.540 0.755
## 12 disa… 매우잘못… 0.645 9.00 5.84e-15 114 0.524 0.740
## 13 disa… 보수잘한… -0.648 -9.01 6.34e-15 112 -0.744 -0.527
## 14 disa… 중도매우… 0.634 8.67 3.82e-14 112 0.509 0.732
## 15 disa… 진보잘못… 0.627 8.53 8.11e-14 112 0.501 0.727
## 16 sinn… 매우잘한… -0.618 -8.40 1.39e-13 114 -0.720 -0.492
## 17 disa… 진보잘한… -0.620 -8.36 1.90e-13 112 -0.722 -0.492
## 18 sinn… 중도매우… -0.615 -8.25 3.51e-13 112 -0.717 -0.486
## 19 sinn… 진보잘못… 0.610 8.15 5.77e-13 112 0.480 0.714
## 20 sinn… 잘한다… -0.604 -8.10 6.73e-13 114 -0.709 -0.474
## 21 disa… 보수모름… -0.603 -8.00 1.27e-12 112 -0.708 -0.471
## 22 sinn… 잘못한다… 0.595 7.90 1.93e-12 114 0.463 0.701
## 23 sinn… 진보잘한… -0.597 -7.88 2.30e-12 112 -0.704 -0.464
## 24 disa… 진보매우… -0.595 -7.84 2.84e-12 112 -0.702 -0.462
## 25 disa… 진보매우… 0.595 7.83 3.01e-12 112 0.461 0.702
## 26 sinn… 중도잘한… -0.593 -7.79 3.68e-12 112 -0.700 -0.459
## 27 sinn… 중도잘못… 0.588 7.69 6.27e-12 112 0.453 0.696
## 28 sinn… 진보매우… -0.580 -7.54 1.30e-11 112 -0.691 -0.444
## 29 sinn… 보수잘못… 0.579 7.52 1.47e-11 112 0.442 0.690
## 30 sinn… 보수잘한… -0.579 -7.52 1.49e-11 112 -0.690 -0.442
## # … with 78 more rows, and 1 more variable: alternative <chr># option 3
mySumm.2 %>% arrange(p.value) %>%
select(word, eval, estimate, everything(), -method) %>%
filter(p.value<.05) %>% print(n = 30)## # A tibble: 121 x 9
## word eval estimate statistic p.value parameter conf.low conf.high
## <chr> <chr> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
## 1 head 중도잘못… 0.779 13.1 2.05e-24 112 0.694 0.842
## 2 head 중도잘한… -0.772 -12.9 8.41e-24 112 -0.837 -0.686
## 3 head 중도매우… 0.765 12.6 3.95e-23 112 0.676 0.832
## 4 head 보수잘못… 0.762 12.5 6.59e-23 112 0.673 0.830
## 5 head 보수매우… 0.761 12.4 8.01e-23 112 0.672 0.829
## 6 head 매우잘못… 0.757 12.4 8.99e-23 114 0.666 0.825
## 7 head 잘못한다… 0.756 12.3 9.72e-23 114 0.666 0.825
## 8 head 보수잘한… -0.752 -12.1 5.60e-22 112 -0.822 -0.659
## 9 head 잘한다… -0.737 -11.6 3.91e-21 114 -0.811 -0.641
## 10 head 중도매우… -0.722 -11.0 1.33e-19 112 -0.799 -0.620
## 11 head g잘못하… 0.731 11.1 1.73e-19 107 0.630 0.808
## 12 head 보수잘하… -0.713 -10.8 5.34e-19 112 -0.793 -0.609
## 13 head 보수매우… -0.706 -10.5 1.80e-18 112 -0.788 -0.600
## 14 head g잘하고… -0.716 -10.6 2.02e-18 107 -0.797 -0.610
## 15 head 진보매우… 0.691 10.1 1.84e-17 112 0.581 0.776
## 16 head 보수모름… -0.688 -10.0 2.57e-17 112 -0.774 -0.578
## 17 disa… 진보매우… -0.682 -9.88 6.38e-17 112 -0.770 -0.570
## 18 head 매우잘한… -0.674 -9.75 1.06e-16 114 -0.763 -0.561
## 19 disa… 매우잘한… -0.669 -9.60 2.38e-16 114 -0.758 -0.554
## 20 disa… 중도매우… -0.635 -8.70 3.26e-14 112 -0.733 -0.511
## 21 head 진보잘못… 0.633 8.65 4.18e-14 112 0.508 0.732
## 22 sinn… 매우잘한… -0.627 -8.60 5.01e-14 114 -0.726 -0.502
## 23 disa… 진보잘하… 0.631 8.62 5.05e-14 112 0.506 0.730
## 24 sinn… 진보잘못… 0.629 8.55 7.08e-14 112 0.503 0.728
## 25 disa… 진보잘못… 0.628 8.53 7.75e-14 112 0.502 0.728
## 26 disa… 진보잘한… -0.625 -8.47 1.07e-13 112 -0.725 -0.498
## 27 sinn… 진보잘한… -0.625 -8.46 1.13e-13 112 -0.725 -0.498
## 28 sinn… 진보매우… -0.624 -8.46 1.17e-13 112 -0.725 -0.497
## 29 disa… 진보잘못… 0.614 8.23 3.81e-13 112 0.485 0.717
## 30 disa… 보수매우… -0.611 -8.17 5.11e-13 112 -0.715 -0.481
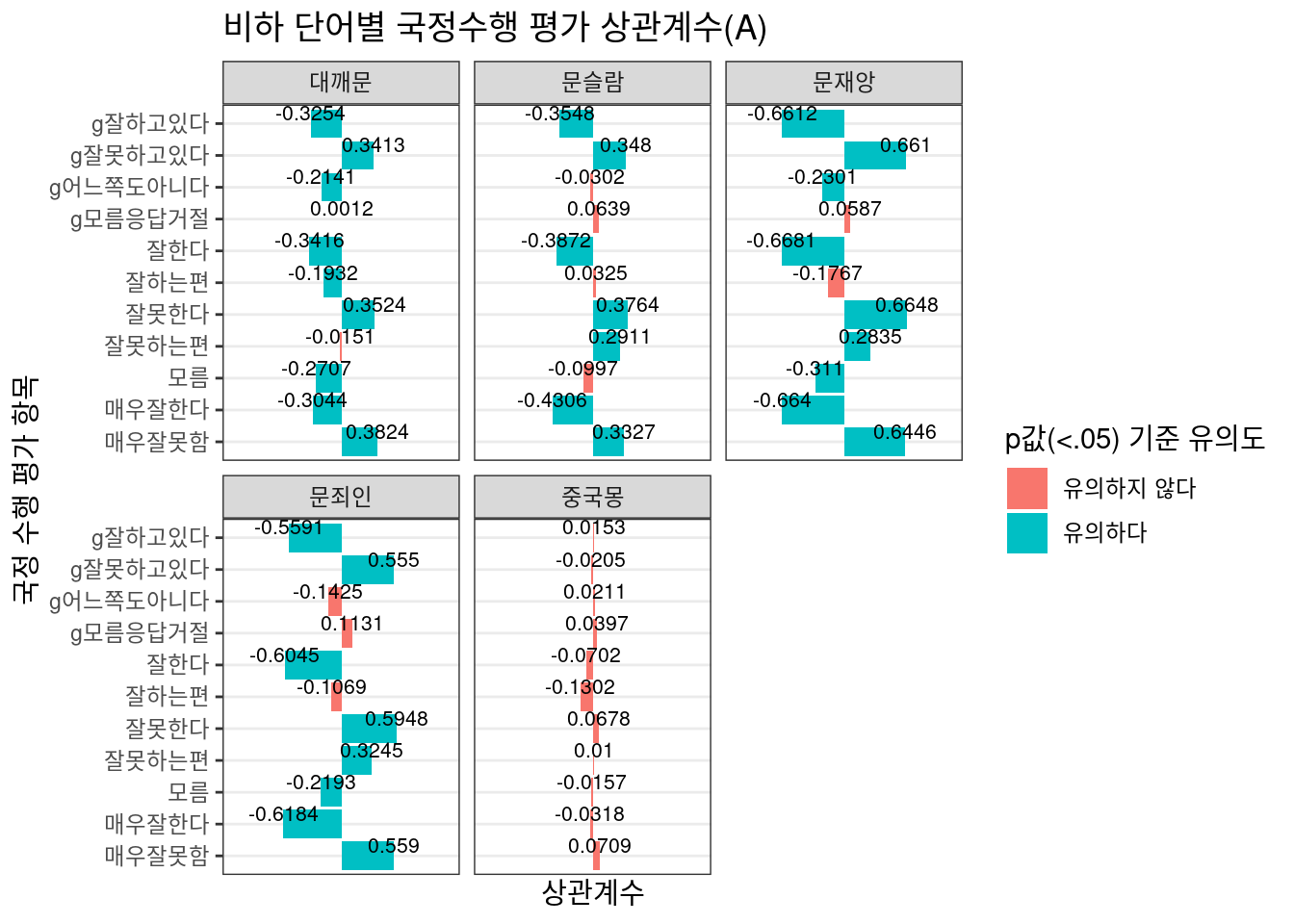
## # … with 91 more rows, and 1 more variable: alternative <chr>상관계수가 높은 상위 30개 항목을 보았을 때 상관도가 높은 단어가 지수별로 상이하게 나옴을 알 수 있다. 가령 댓글 좋아요와 싫어요를 단순 비교한 Option 2의 경우 ‘문재앙’ 댓글이 높은 상관도를 보이는 반면, 전체 댓글 수 대비 비하 단어 포함 댓글 수를 로그 변환 후 반영하는 Option 3의 경우 ‘대깨문’ 댓글이 높은 상관도를 보이고 있다.
이제 ggplot2 패키지를 통해 2개 지수의 상관계수를 단어별로 시각화하여 살펴보도록 하자.
단어별 시각화
Option 2
Option 3
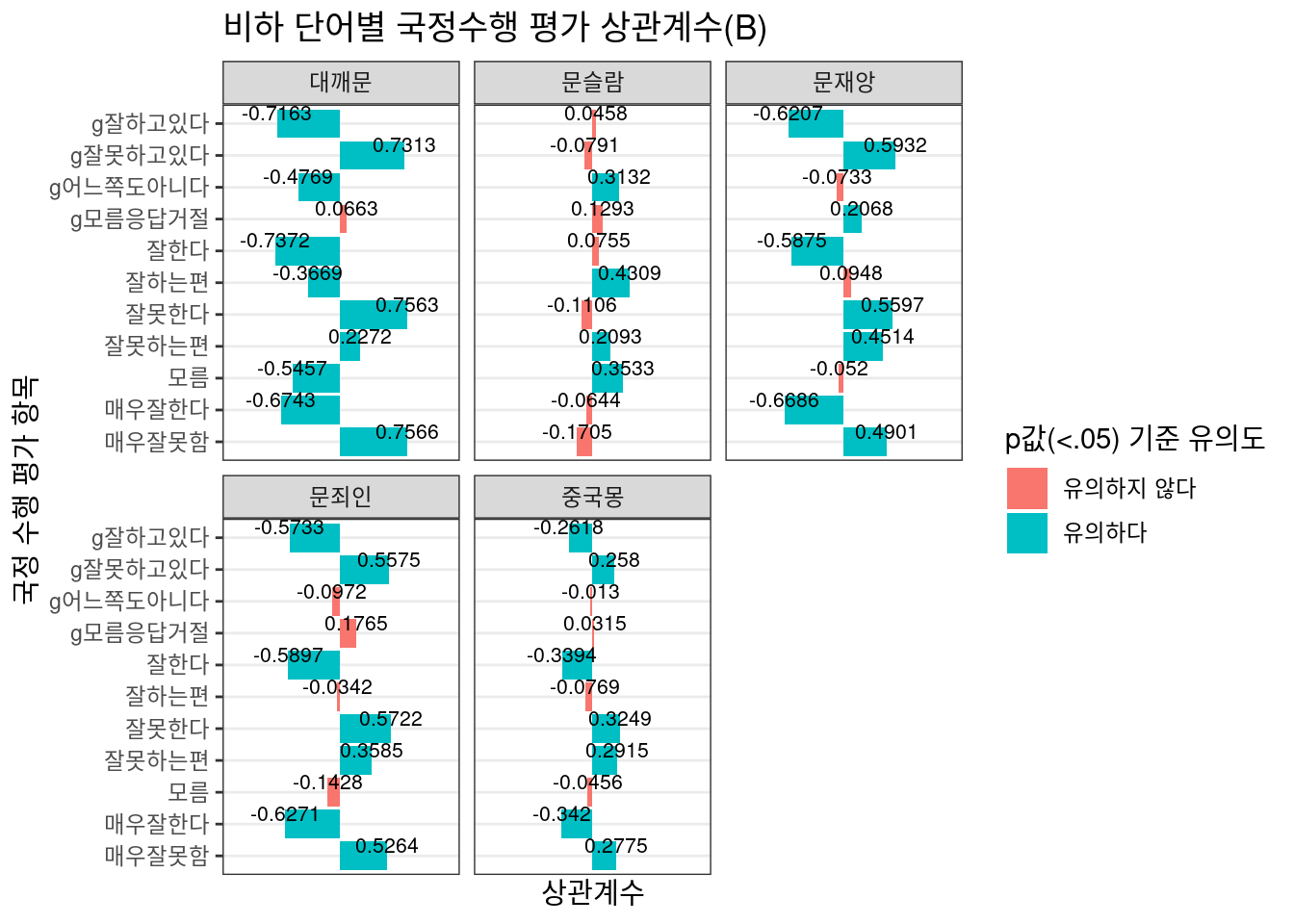
Option 2에서는 ‘중국몽’, Option 3에서는 ’문슬람’과 댓글 지수가 거의 무관한 것으로 추정된다. 따라서 각 수식의 이후 시각화에서 해당 단어는 제외했다.
부정/긍정평가 시각화
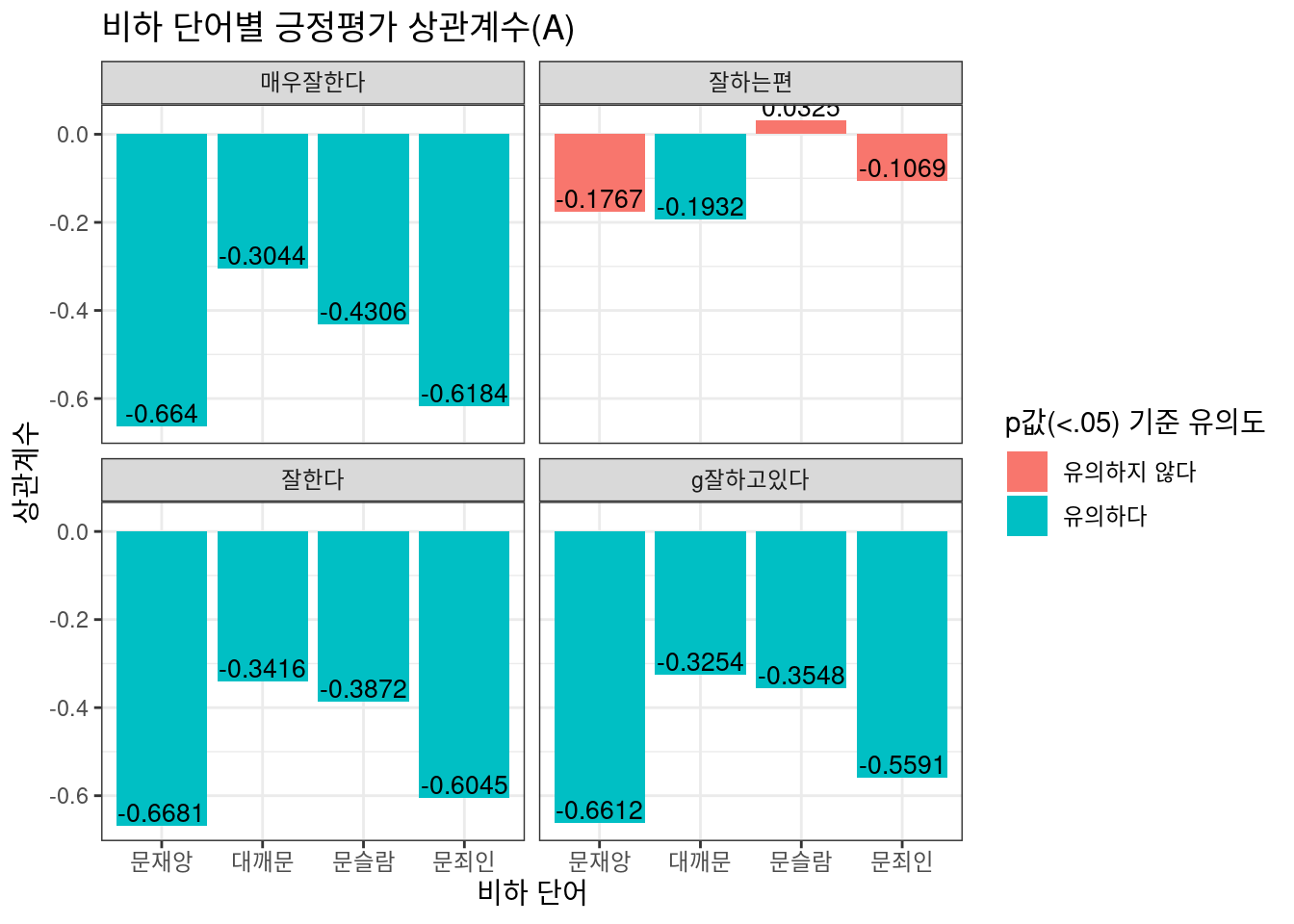
국정수행 부정평가와 긍정평가 두 수치와 Option 2,3 식의 상관관계를 시각화해보자. 여론조사 항목에서 ’잘못’이 들어가면 부정평가 항목이며 긍정평가 항목은 |을 이용하여 일일이 필터링 전처리를 해준다. 비하 단어와 여론조사의 상관도를 살펴보고 있는만큼 상식적으로라면 부정평가와 더 많은 호응을 할 것이다. 즉, 시민들은 대통령에 대한 부정적 평가와 비하 단어 사이에서 더 긴밀한 연관을 보이고 있을 것이다. 그런데 과연 그럴까?
Option 2
mySumm %>%
filter(str_detect(eval, "잘못")) %>%
mutate(colors = ifelse(p.value<0.05, 'valid', 'invalid')) %>%
filter(!str_detect(word, "china")) %>%
filter(!str_detect(eval, "보수") & !str_detect(eval, "진보") & !str_detect(eval, "중도")) %>%
ggplot(aes(x = word, y = estimate, fill = colors)) +
ggtitle("비하 단어별 부정평가 상관계수(A)")+
geom_bar(stat = "identity") +
geom_text(aes(label=round(estimate,4), vjust=-0.2), size = 3.5) +
xlab("비하 단어")+
ylab("상관계수")+
scale_x_discrete(labels = c("문재앙", "대깨문", "문슬람", "문죄인"))+
scale_fill_discrete(name = "p값(<.05) 기준 유의도", labels = c("유의하지 않다","유의하다"))+
theme_bw()+
facet_wrap(~eval)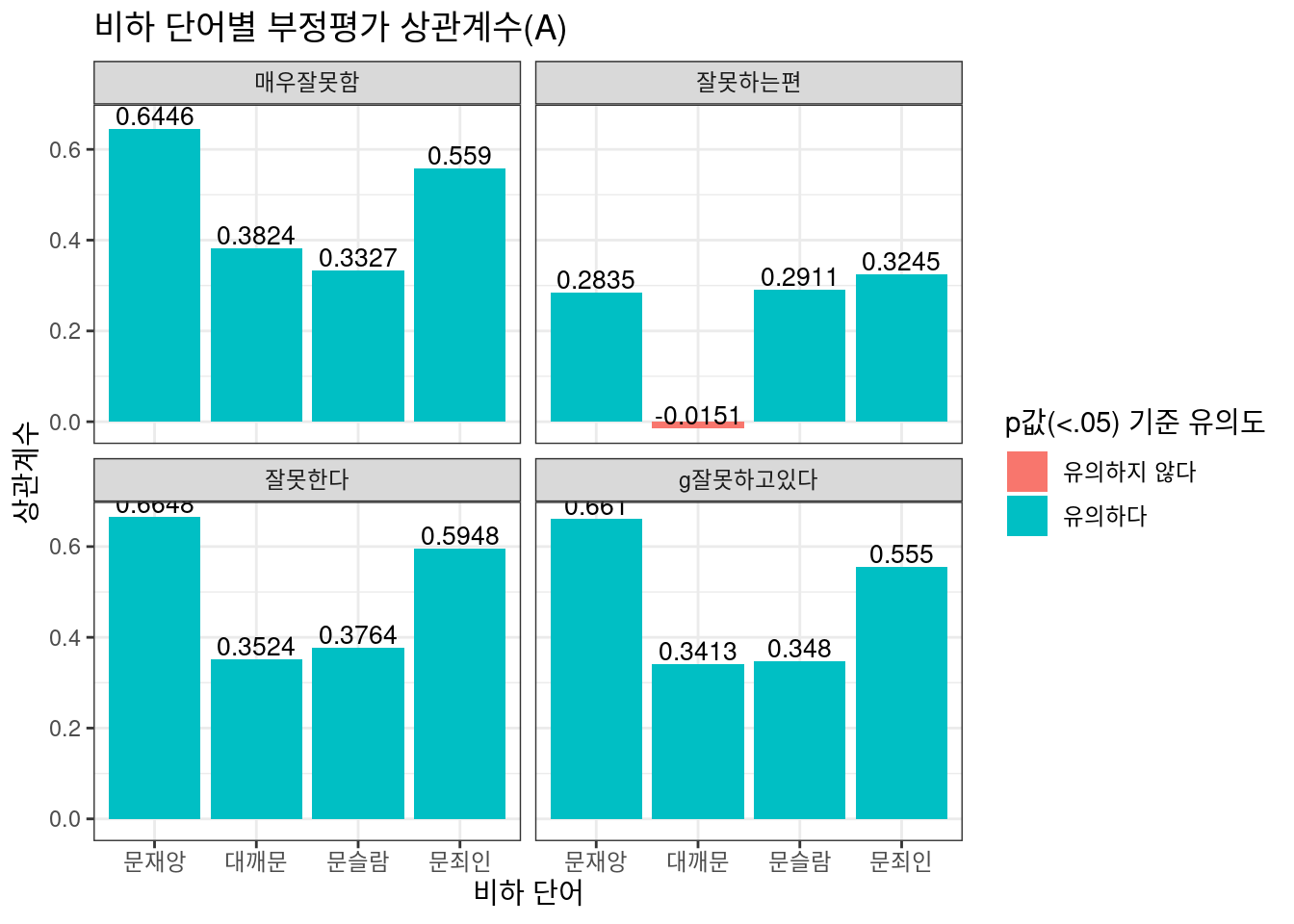
Option 3
mySumm.2 %>%
filter(str_detect(eval, "잘못")) %>%
filter(!str_detect(word, "islam")) %>%
mutate(colors = ifelse(p.value<0.05, 'valid', 'invalid')) %>%
filter(!str_detect(eval, "보수") & !str_detect(eval, "진보") & !str_detect(eval, "중도")) %>%
ggplot(aes(x = word, y = estimate, fill = colors)) +
ggtitle("비하 단어별 부정평가 상관계수(B)")+
geom_bar(stat = "identity") +
geom_text(aes(label=round(estimate,4), vjust=-0.2), size = 3.5) +
xlab("비하 단어")+
ylab("상관계수")+
scale_x_discrete(labels = c("중국몽", "문재앙", "대깨문", "문죄인"))+
scale_fill_brewer(name = "p값(<.05) 기준 유의도", labels = c("유의하다"), palette = "Set2")+
theme_bw()+
facet_wrap(~eval)
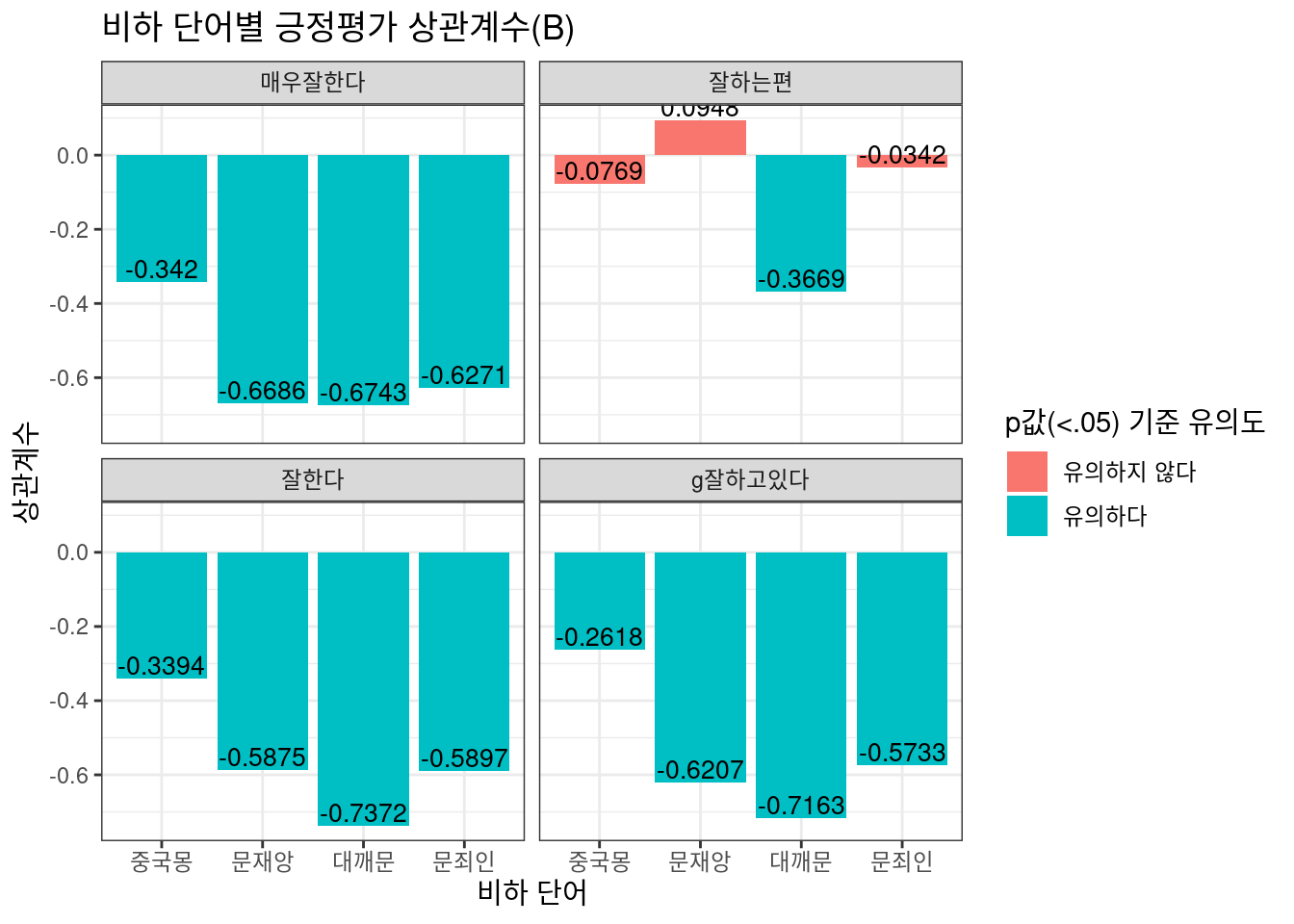
상식에 기반한 추측과는 달리, 긍정평가 부정평가 모두 비슷한 상관계수를 보이고 있다. 댓글 좋아요 비율만을 반영하는 Option 2는 주로 ‘문재앙’, ‘문죄인’ 포함 댓글과, 로그값으로 변환된 작성 댓글 수를 반영한 Option 3의 경우 ‘대깨문’ 포함 댓글이 높은 상관도를 보이고 있다. 또한 긍/부정평가 모두 ‘잘하는 편’, ‘잘못하는 편’ 등 중도평가에서 다소 애매한 수치를 보이고 있는 점 역시 흥미롭다. 중도평가를 내리는 이들은 비하 단어 포함 댓글에 상대적으로 덜 호응하고 있다고 볼 수 있는 것이다.
급진/중도평가를 나누어 시각화하여 이 부분을 좀 더 자세히 들여다보자. 어떤 현상을 포착할 수 있을까? 그리고 이번에는 세부 정치성향별 여론조사 항목도 함께 넣어보자. 보수 성향 응답자와 진보 성향 응답자 사이에는 어떻게 눈에 띄는 차이가 발견될까?
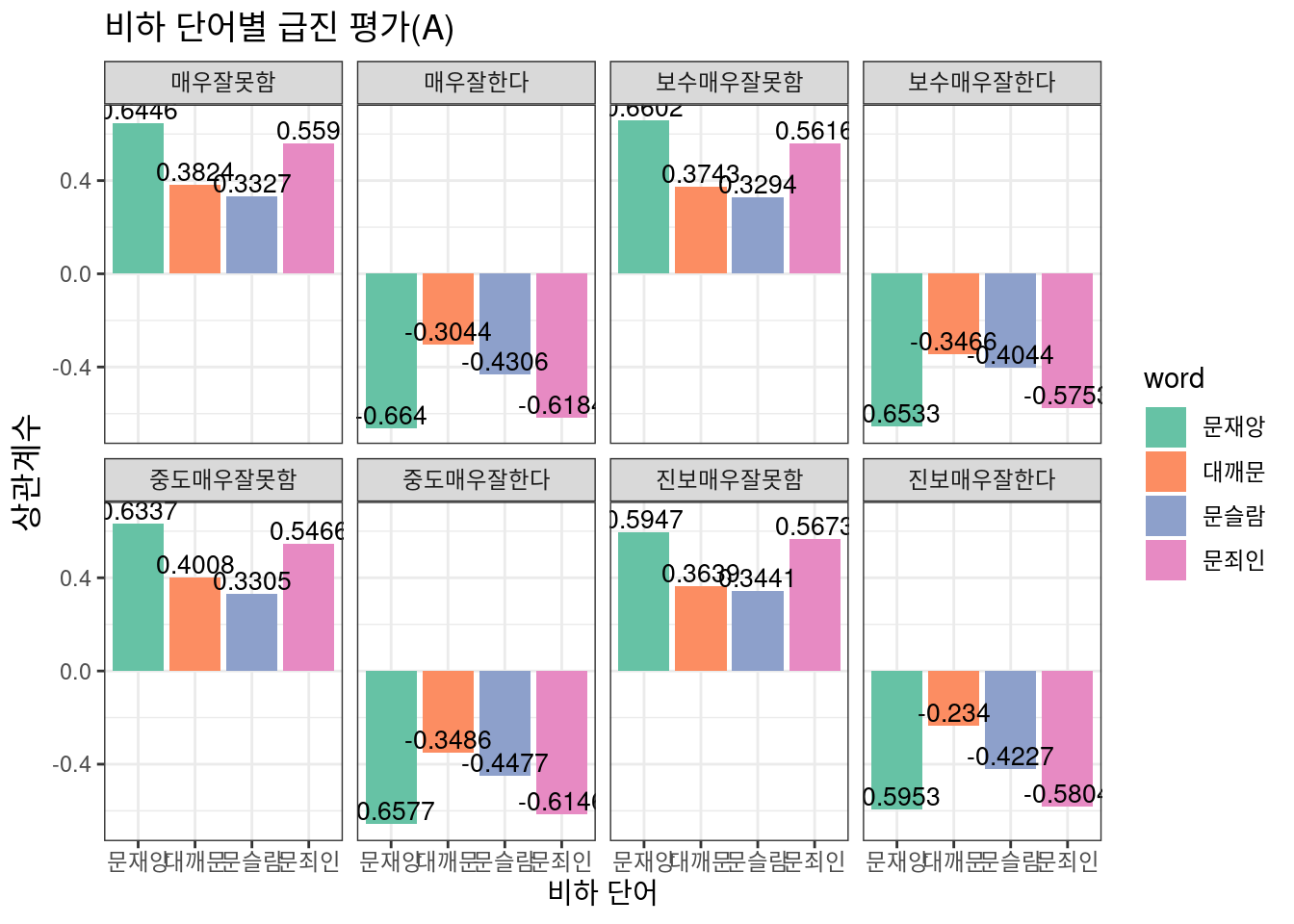
급진/중도평가 시각화
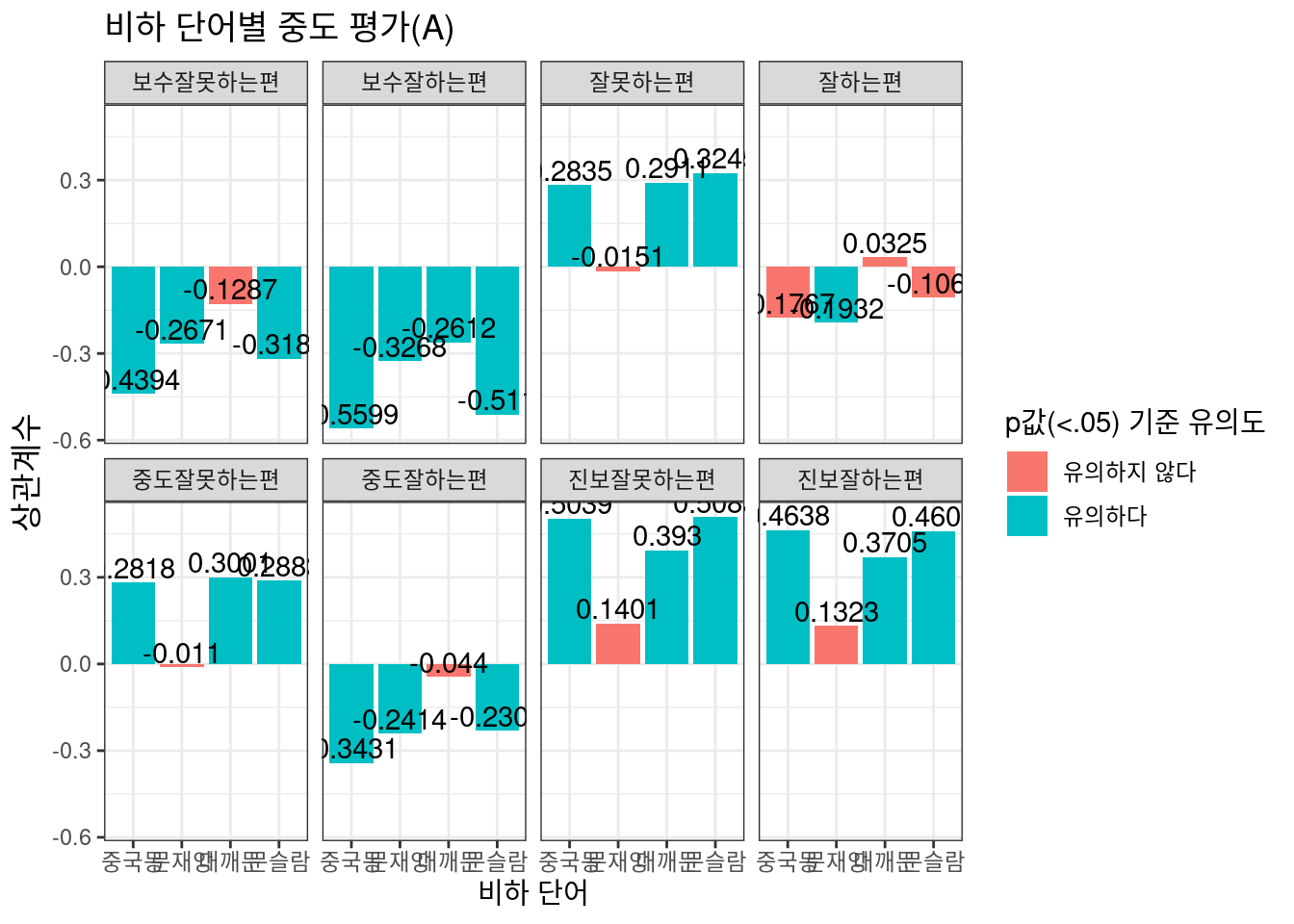
Option 2
option 3
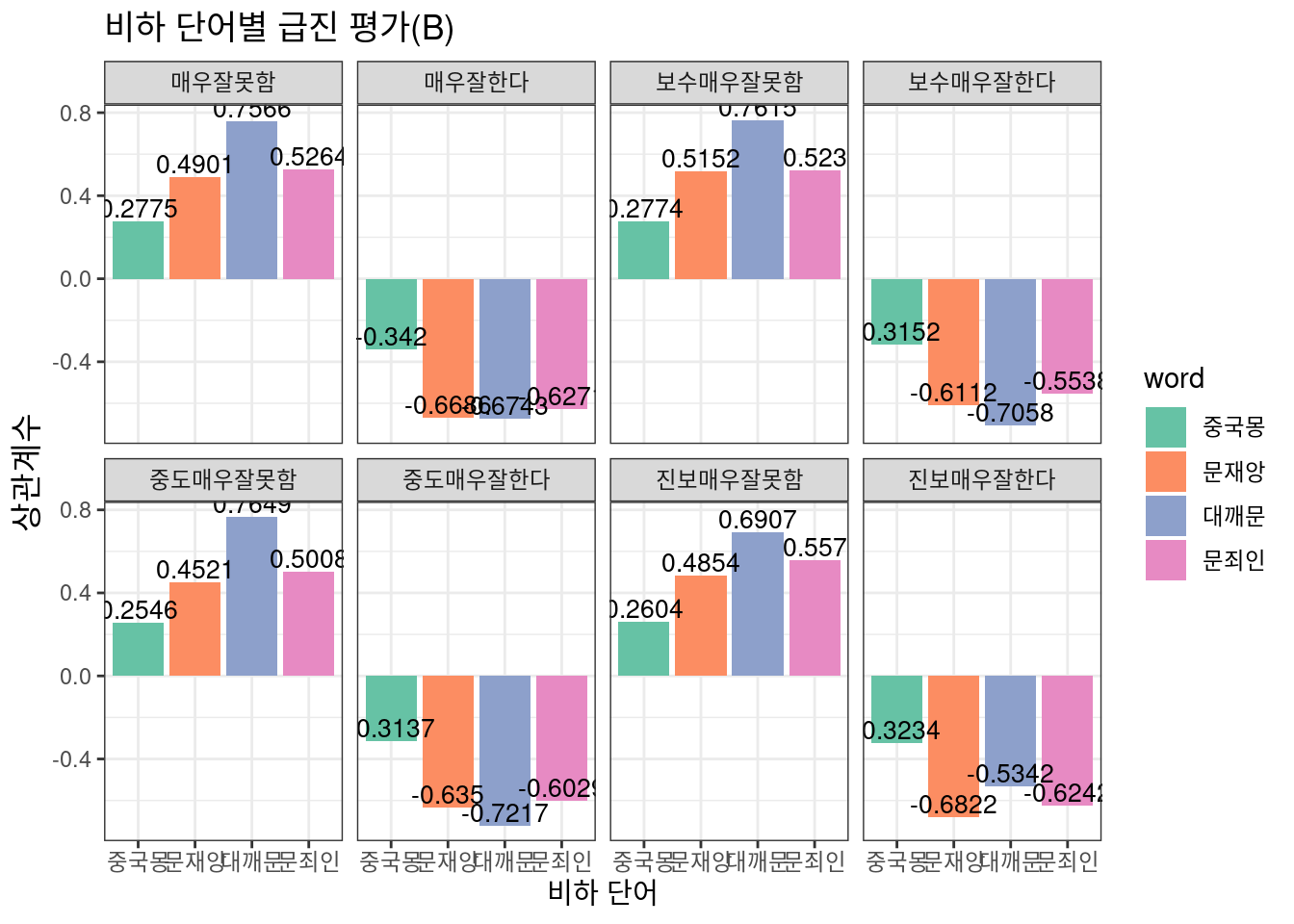

우선 급진평가에서는 Option 2와 Option 3에서 모두 뚜렷하고 일관된 결과를 보이고 있다. 즉 여론조사 항목과 직접 계산한 비하 댓글 지수가 나름대로 적절히 호응하고 있으며 이는 대통령 국정수행에 대해 다소 급진적인 의견을 가진 이들이 비하 댓글이라는 proxy를 통해 적절히 대표되고 있음으로 해석할 수 있을 것이다. 그런데 중도평가 항목에서는 그렇지 않다. 눈에 띄는 현상으로는, 보수 성향 응답자와 진보 성향 응답자의 치우침이 있다.
마지막으로, 상관관계 추이를 살펴보자. 조사기간이 120주였던 만큼, 이를 4부분으로 나누어도 상관도를 파악하기 적절한 표본 수를 보장받을 수 있을 거라고 판단했다. 우선 앞 2부분, 즉 2018.2~2019.4는 대통령 지지도가 꾸준히 하락한 시점이며 뒷 2부분 2019.4~2020.5는 레임덕 현상으로 지지율이 지지부진하며 코로나 사태로 국정 변동이 심하던 시점과 맞물린다. 따라서 시간이 지날수록 비하 단어와 국정평가의 상관도는 상대적으로 감소해왔을 것이라고 상식적인 추측을 해 볼 수 있다.
과연 그럴까?
상관관계 추이 시각화
상관관계 추이를 살펴보기 위해 다음과 같은 for문 코드를 작성한다. 120주를 4번의 구간으로 분할한 후 각 구간별로 여론조사 항목과 비하 단어 지수의 상관도 테스트를 거칠 것이다.
myChange = tibble()
for (k in 1:4){
for (i in colnames(Summary.df[1:5])){
for (j in colnames(Summary.df[24:34])){
formula = as.formula(str_c("~",i,"[",as.character(1+(k-1)*30),":",as.character(30*k),"]+",j,"[",as.character(1+(k-1)*30),":",as.character(30*k),"]"))
myCorr = cor.test(formula, data = Summary.df) %>% tidy() %>%
select(estimate, p.value, conf.low, conf.high)
myCorr$word = i
myCorr$eval = j
myCorr$session = k
myChange = bind_rows(myCorr, myChange)
}
}
}이하 그래프 별로 코드가 거의 비슷하므로 ggplot 코드 하나만을 보자면 다음과 같다.
myChange %>%
filter(eval == "잘한다" | eval == "잘하는편" | eval == "매우잘한다" | eval == "g잘하고있다") %>%
mutate(colors = ifelse(p.value<0.05, 'valid', 'invalid')) %>%
ggplot(aes(x = session, y = estimate)) +
ggtitle("조사기간별 상관계수 추이(A)")+
geom_bar(aes(fill = word), stat= "identity", position = "dodge") +
xlab("조사기간\n(4분할)")+
ylab("상관계수")+
scale_x_continuous(breaks = c(1,2,3,4), labels = c("'18.02~\n'18.08","'18.09~\n'19.03","'19.04~\n'19.10","'19.11~\n'20.05"))+
scale_fill_discrete(name = "word", labels = c("중국몽", "문재앙", "대깨문", "문슬람", "문죄인"))+
theme(axis.text = element_text(size = 8))+
theme_bw()+
facet_wrap(~eval)
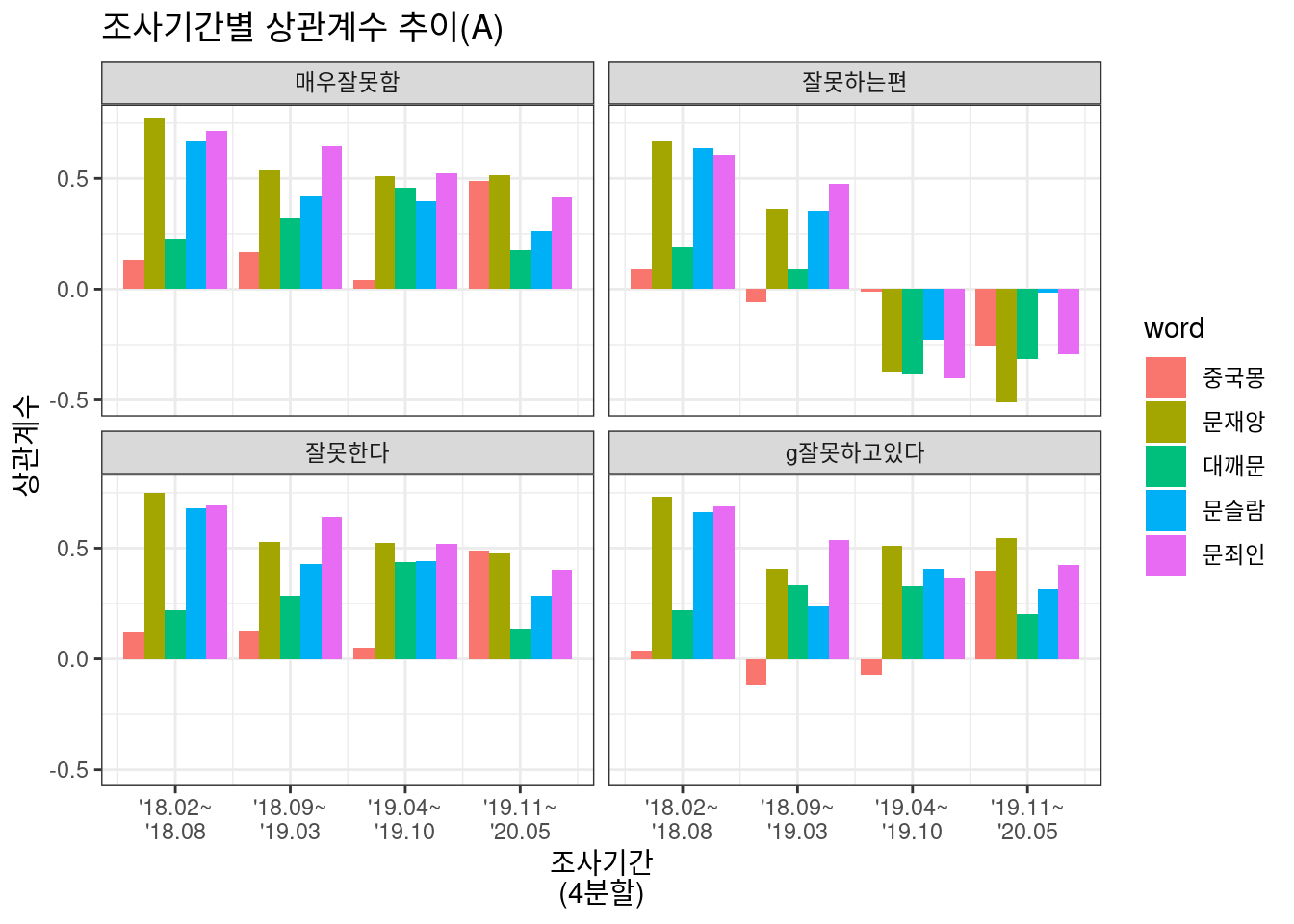
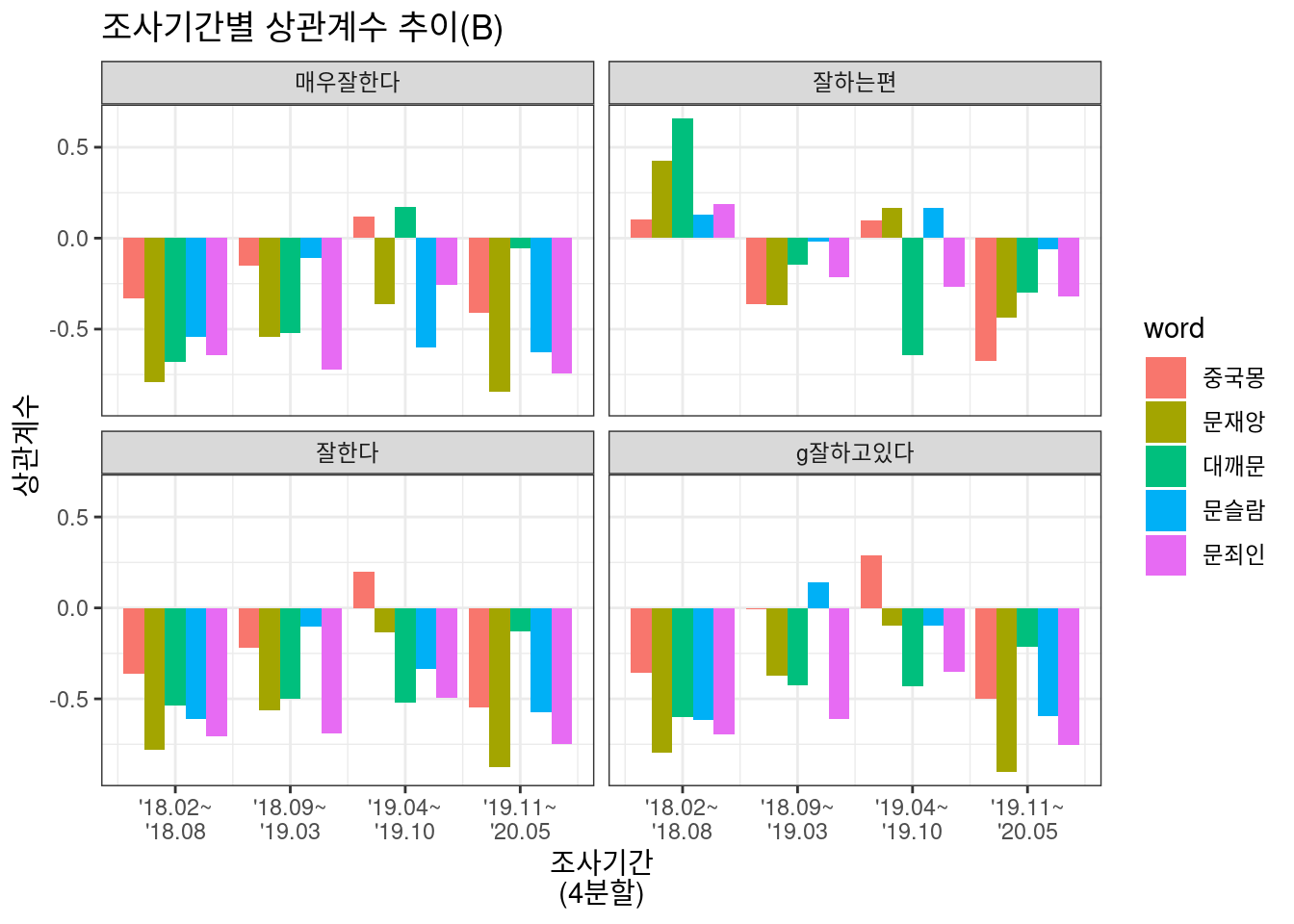

Option 2와 3에서 조금씩, 그리고 비하 단어별로 다소 난잡한 차이는 보이지만, 대체로 구간이 지날수록 상관도가 조금씩 줄어들며, 특히 중도 평가 항목(“잘하는편”, “잘못하는편”)에서는 상관도가 거의 없다고 볼 수도 있겠다. 즉 레임덕 기간에 대통령에 대해 중도평가를 내리는 이들은 대체로 대통령에 대해 큰 기대나 실망이 없기에 비하 단어에 굳이 반응하지 않고 있는 것으로 볼 수 있겠다.
주관적 분석
이번 상관도 분석에서 개인적으로 가장 흥미로웠고 확실히 말할 수 있는 지점은, ‘중국몽’과 ’문슬람’과 같이 특정 국가나 종교를 비하하는 맥락을 함유한 단어의 사용이나 여론과의 호응이 저조했다는 점이다. 대통령에게 책임을 귀인하는 듯한 ’문재앙’ ‘문죄인’ 등의 비하 단어나 심지어 대통령 지지 집단 비하 단어인 ‘대깨문’ 보다 여론과의 호응(상관도)가 낮았다는 사실에서 우리는 이러한 단어의 사용이 특히 정치적인 레토릭으로 다분히 활용되고 있다는 인상을 받는다.
물론 해석은 모두 다를 것이다.
끝